Analytics plays a big role at Leadfeeder.
We take pride in making informed decisions by using the vast amount of data our business generates.
Within our AWS infrastructure, we've developed a Data Warehouse solution and adopted the serverless paradigm to support analytics.
It allows cost-savings on infrastructure and enables us to develop, maintain, and evolve our pipelines more efficiently.
To fulfill reporting requirements, we make use of Tableau Online, a cloud-based solution for Business Intelligence.
So, what does "serverless" mean?
Per AWS:
"Serverless is a way to describe the services, practices, and strategies that enable you to build more agile applications so you can innovate and respond to change faster. With serverless computing, infrastructure management tasks like capacity provisioning and patching are handled by AWS, so you can focus on only writing code that serves your customers. Serverless services like AWS Lambda come with automatic scaling, built-in high availability, and a pay-for-value billing model. Lambda is an event-driven compute service that enables you to run code in response to events from over 150 natively-integrated AWS and SaaS sources - all without managing any servers."
Sounds pretty good, no? 😎
No more infrastructure management to focus on what matters — process and analyze data to steer the business and product development.
In practice, it’s not all that simple. We have a huge data volume, mostly from our product data, and handling this volume poses several challenges.
Our serverless pipelines

As you can see in the diagram above, the main components we use for data processing are AWS Glue and AWS Lambda.
Glue is essentially a managed service for Spark, while Lambda provides serverless compute.
Both of them allow us to develop and deploy code quickly.
For example, with Glue, there's no need to manage a cluster, which is a huge advantage.
Managing a Spark cluster can be overwhelming, eventually leading a team to focus on monitoring, maintaining nodes up, and ensuring jobs are submitted correctly.
Glue allows us to write a job, specify the capacity + a few additional configuration parameters, and run the job.
Of course, there are a few caveats to all this.
AWS automatically provisions a cluster when a job is executed, and that cluster can take some time to be available. This is painfully true for the initial versions of Glue, but AWS has somehow mitigated this in the latest version (2.0 at the time of writing).
We do lose the fine-grained control that traditional Spark job submission provides. However, that seems more like an advantage, given the complexity of keeping all the job submission parameters in line with the cluster capabilities and availability.
An additional, interesting feature of AWS Glue is the Data Catalog.
This metadata repository, with which we can easily establish a parallel to the Hive Metastore, can hold schemas and connection information about data sources from different systems, including AWS S3.
To update this repository, Glue includes a Crawler that can automatically maintain the schemas by scanning the source systems.
To use these data sources in our jobs, we can easily just reference the catalog.
data = glueContext.create_dynamic_frame.from_catalog(
database="mydb",
table_name="mytable")
This renders the code in our Glue jobs to be data source-agnostic.
Plus, as the Data Catalog can collect schemas from different systems, it provides a single unified location where all our data can be described.
We also make heavy use of Lambda for the support of multiple programming languages.
For analytics, we use Python, but other departments use different programming languages. Lambda provides great flexibility as you can choose whichever programming language suits best for a given problem without installing anything on any server or instance. Just create the Lambda function and start coding!
In our case, we need to read data from Elasticsearch and Cassandra, undertake some processing on that data, and load it to our Data Warehouse.
When reading data from these systems, we need to be very careful to keep their load low to not affect how they are serving our customers.
But at the same time, the amount of data these systems possess is huge and naturally a tremendous source of value for our product analytics.
To extract data while keeping the load low, we extract many small batches of data.
Lambda has a 15-minute maximum execution time limit, so we cannot extract all data from each source with one function execution.
To get around this, we chain Lambda executions.

By passing a state object between function runs and updating this object in every run, we can maintain a pointer indicating where processing should start and load a small batch of data in each run.
Each function instance invokes the next until the data has been processed.
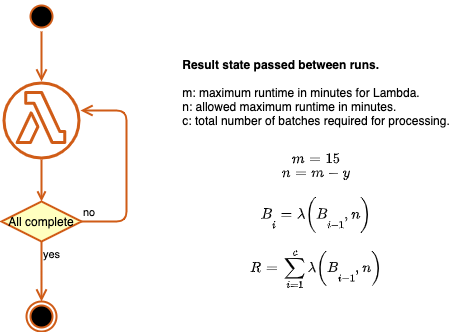
This isn't ideal, so we started looking for alternatives that allow us not to worry about time limitations.
AWS provides Batch service which is designed for engineers and scientists to run large compute batch jobs. You create a compute environment, associate it with a job queue and then define job definitions that specify which container images to run.
In comparison to Lambdas, it requires a bit more setup, but on the other hand, you don’t need to worry anymore about time limitations. We are currently using it to run heavy aggregations in our DWH - task, which was hard to do with just lambdas.
Even though Glue, Lambda, Batch enable fast code development and deployment, QA can be troublesome.
As more critical and complex pipelines are developed, ensuring the proper tests take place is somehow difficult. It is impossible to replicate the serverless environment locally for unit testing.
Setting up a dedicated serverless test environment with enough meaningful data and metadata is quite a challenge, not to mention the cost implication.
To mitigate this, for Glue, we create Glue Development endpoints whenever necessary to test code artifacts before promoting them into production.
For Lambda, as we use Python, we create local virtual environments where we can run unit tests and then package our applications.
Also, we use PostgreSQL docker image to simulate Redshift, which is also not ideal because there are sometimes significant differences between those databases.
AWS Step Functions orchestrate our pipelines
To orchestrate our pipelines, we use AWS Step Functions.
Step Functions a fully managed service, meaning you do not need to configure any instances.
Step functions rely on the concept of state machines, and they can be implemented as JSON documents. Amongst many other features, they allow running jobs synchronously and asynchronously, handle dependencies, parallel executions, etc.
And of course, Glue, Lambda, and Batch are fully integrated with Step Functions. Arguably, a tool supporting DAG (Direct Acyclic Graph) could be more suitable for intricate batch pipelines, however until recently, no such tool was available in AWS as a managed service.
AWS now provides Apache Airflow as a managed, serverless service. For sure, we will be evaluating this in the future, but the truth is, Step functions have served us well. They are easy to implement and maintain and provide all the features we require.
Our cloud Data Warehouse
As we rely on AWS, Redshift is the natural choice for our Data Warehouse. It presents many advantages and a few shortcomings, for which I will not go into detail.
Redshift fits our serverless approach as there is no server management involved and scaling both vertically and horizontally is a relatively simple process.
Also, production-like features such as workload management and automated snapshots are available, making it a great solution within AWS to support our analytics function.
Also, query performance is satisfactory and capable of supporting our reporting requirements.
Recently we also started working on adding AWS Spectrum to our stack.
Spectrum allows querying external data, for example, one stored in S3, so you don’t need to import data into the database.
Reports, report!
Our reporting is done with Tableau Online, a cloud-based analytics service. It is the only analytics component outside of our AWS infrastructure..
On Tableau Online we can build and share reports, schedule extracts, create ad-hoc analysis, all in a very pleasant user interface — the stuff of dreams for analysts (right?!).
Without going into much detail, it provides what we require without having to manage any servers and scales seamlessly.
As expected, Tableau also presents its challenges. Mainly because it has a direct connection to the database, and analysts can publish reports with arbitrary SQL code and schedule it to run.
To address this issue we have implemented few data governance measures such as separate queues in Redshift for Tableau users with limitations on resources.
We also started a process of moving extracts schedule to instead become part of ETL (vs using Tableau UI). This way, we'll control what queries and at what time they will be running for reporting purposes; this is mostly done via Tableau API.
The end goal we have here is to integrate Tableau into our data infrastructure and manage it as any other component we have.
Our serverless approach accelerates our analytics & what this means for future work
Our serverless approach has proven to enable and accelerate how analytics are available to our business.
This does not come without its own challenges and limitations, but it does allow significant cost savings while delivering consistent quality and facilitating agile change management.
As more serverless tools are made available, careful consideration should be undertaken to choose the more appropriate tools, evaluating their costs and benefits.
From our experience, the pros and cons to serverless analytics are:
Pros:
No server management. No need to manually manage server instances. All the compute resources can be easily configured.
Reduced cost, only pay for infrastructure when used.
Fast deployments.
Cons:
Testing and debugging are quite challenging. Difficult to replicate the environment locally.
Not very good for long-running processes, due to Lambda limits.
Quite complicated to add components outside of the AWS stack.
Stay tuned. More on this to come soon!

João is a self-motivated engineer, passionate about data warehousing and data engineering. He enjoys discussions about technology and creative ways to approach complex problems. If you favor the same topics, hit him up on LinkedIn.

Natalia has worked with data for almost 10 years as engineer, analyst, and scientist. Talk numbers with her on LinkedIn.
Get more from your web analytics.
t’s time to turn your website traffic data numbers into something more meaningful. Website visitor analytics enable you to identify and qualify the companies visiting your website, even when they don’t fill out a form.
Show me how
