Idea to provision infrastructure on demand, when you need it and in the right size, got my curiosity from the moment I heard about it.
It was when I was introduced to AWS Lambda functions.
The design of the AWS Lambda service dictates certain limitations. Execution timeout and memory available are good examples. In my case, those most often rendered Lambda functions as an inappropriate tool for the task.
Still, the ideas behind the Lambda service are clever, generally applicable, and useful. Two are particularly interesting to me…
Infrastructure on demand, because there’s no need for infrastructure to exist if it’s not going to be used. To emphasize this principle — there is no need to pay for infrastructure if it’s idling.
Scalability on demand, because sometimes, there’s a need for more computing power.
Now, off to making AWS EMR our super Lambda …
Data processing that demands high computational power isn’t cheap. The more data there is to process, the more it costs to store it, scan it, and deduce anything meaningful from it. AWS EMR (Elastic Mapreduce) is one of the tools I used the most for tackling problems of this nature.
I can tell you, the costs of using it can pile up quite fast.
About AWS EMR
AWS EMR service provisions clusters of computers and provides us with their computational power. This can also tell us what a proper use case for EMR could be. A very loose definition… It could be a choice when traditional data querying/processing tools are not giving results in a reasonable time.
For example, a SQL query fired against MySQL gives results in twelve hours.
Apache Spark application or Apache Hive query, which both can run on AWS EMR, might be a better choice.
A single EMR cluster consists of several components:

Master node (or up to three master nodes) A master node manages the cluster and runs the cluster resource manager. It also, as AWS docs say, “runs the HDFS NameNode service, tracks the status of jobs submitted to the cluster, and monitors the health of the instance groups”.
Core nodes Core nodes perform computational tasks and coordinate data storage as part of HDFS. They are managed by the master node. There can be only one core node instance group.
Task nodes Task nodes are the basic foundation of cluster computational power. Being that, they only perform computation tasks. There can be up to 48 task node instance groups, with uniform instance types chosen for each of them.
A minimal EMR cluster would have a single master node and, let’s say, two core nodes. A reasonable master node could be an instance of m5.xlarge type. Core nodes can be something like r5.xlarge instances.
This already is not a trivial setup, not to mention its cost, compared to an AWS Lambda function.
We can add to that a task node instance group… r5.2xlarge or r5.4xlarge instances. That's getting very expensive quickly!
This is where we can “steal” from AWS Lambda. We can take those two principles and incorporate them into our usage of AWS EMR.
EMR infrastructure on demand
Cluster creation
We can create an EMR cluster only when it is needed and shut it down when it is not needed anymore.
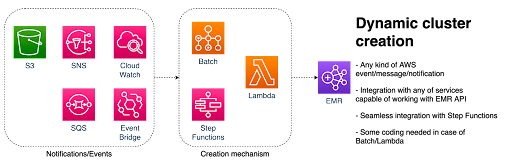
As the image above describes, an EMR Cluster can be created dynamically, when it is needed. That can be triggered by any kind of event or a message coming from any of AWS services.
For example, we want to create an EMR cluster. It should happen when some data arrives in AWS S3, i.e. when an object in AWS S3 is created.
Another use case would be to create an EMR cluster as part of scheduled processing. This can be triggered by an AWS CloudWatch cron event.
Regardless of which event we decide to react to, we need a tool to run our creation mechanism. It can be a Step function, a Batch job or a Lambda function, for instance.
Workload submission
Once an EMR cluster is created, the workload can be submitted in the form of an array of EMR steps. Using Python Boto3 library, for instance, it can be done either on the cluster creation
emr_response = emr.run_job_flow( ..., Steps=steps_definition, … )
or through a separate call to AWS EMR service
emr.add_job_flow_steps( JobFlowId='string', Steps=[...] )
Cluster destruction
What is going to happen with the cluster when it is done with the work? We might want to leave it up and running for possible future workload submission. But let’s assume that is not the case — we want to shut it down.
In that case, there is a detail that needs to be taken care of upon cluster creation:
emr_response = emr.run_job_flow( ..., ScaleDownBehavior="TERMINATE_AT_TASK_COMPLETION" )
By specifying this scale-down behavior to EMR, the cluster will be destroyed when all it is done with all the work.
Step failure
What happens if a single EMR step fails?
We don’t want to leave that cluster running idle just because it didn’t reach the last step and shut down gracefully.
What we do want is to define its behavior in case of a step failure by specifying for each step submitted:
"actionOnFailure": "TERMINATE_CLUSTER"
By doing all this, we can be sure we are safe from AWS cost creep. Also, the principle of “Infrastructure on demand” can be considered implemented.
Scalability on demand
How to implement the scalability on demand principle?
By using EMR’s built-in auto-scaling feature.
Attaching an auto-scaling policy to an EMR cluster, enables it to scale depending on the needs.
The auto-scaling policy should have at least two rules but can have more than that. One rule should tell the cluster when to grow and another to tell it when to shrink.
The scale-out rule could be something like: “if available cluster memory becomes less than 15% and stays like that for more than 5 minutes, this cluster should grow one of its task instance groups by 5 instances”.
A scale in the rule could be something like: “if available cluster memory becomes more than 75% and stays like that for more than 3 minutes, this cluster should shrink the same task instance group by 3 instances”.
A proper auto-scaling policy definition for an EMR cluster can be seen below. here.
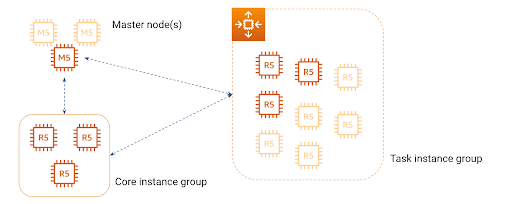
Implementing this principle puts us in a position to have a workflow of:
starting with a cluster of a minimal size
when the cluster’s workload comes in and becomes too heavy for its current size, the cluster grows
when the load on the cluster wears off, it shuts down some of the worker instances and shrinks in size
EMR in summary
These two principles applied together almost make an EMR cluster a kind of an AWS Lambda function. A "Lambda" that is slow to start, but has almost limitless computational power, memory and processing time.
As with all things, something’s gotta give a significant bootstrap time. It takes around ten minutes to provision a cluster.
If the bootstrap time is not an issue, the EMR approach allows you to unleash automatically scaled and provisioned processing power while also bypassing the Lambda’s memory and timeout limits.

Natalia has worked with data for almost 10 years as engineer, analyst, and scientist. Talk numbers with her on LinkedIn.
Get more from your web analytics.
t’s time to turn your website traffic data numbers into something more meaningful. Website visitor analytics enable you to identify and qualify the companies visiting your website, even when they don’t fill out a form.
Show me how

